The Boom of Large Language Models and Image Generation
In 2015 when Google released Deepdream the idea of machine creativity captivated my mind for a short while, I tried to run the code but it was very impractical and my interest soon waned. Later on I read Superintelligence by Nick Bostrom (in 2016) and ever since I’ve always been fascinated by the idea that the age of machines would soon be upon us. The concept and the myth of the Technological Singularity is scary, grandiose, ethereal and a fertile ground for science (and personal) fiction. Since then progress was relatively slow but it seems that we are currently approaching an inflection point, this area of interest dear to me has become so prolific and fast-paced that I feel the need to start taking notes to declutter a bit my mental map. Paradigm shit after paradigm shift the giant leaps peculiarly keep coming!

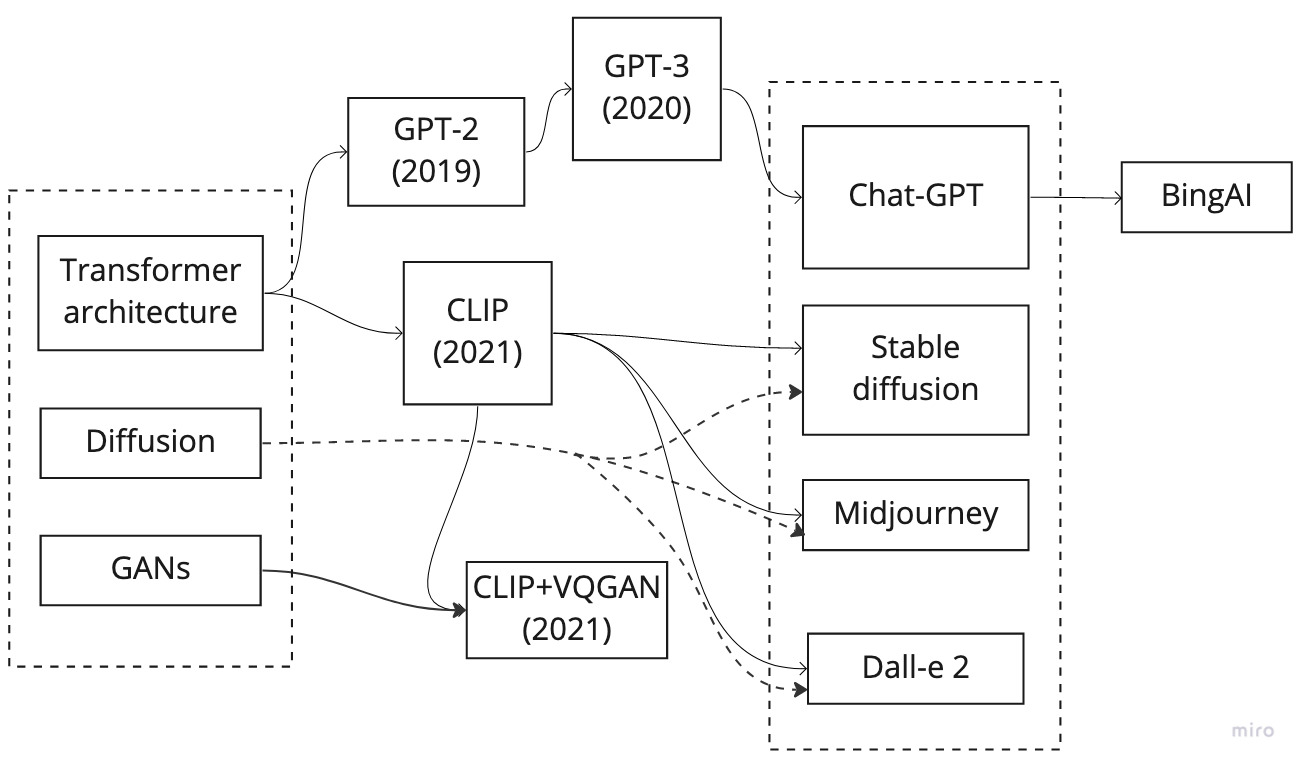
In the last 2 years, there has been a significant boom in the development of large language models and image generation tools. These tools have the ability to generate realistic and coherent text and images, respectively, and have garnered a lot of attention from researchers, artists, developers, and the general public. You’ve probably heard about LLMs, ChatGPT, CLIP, GPT-3, GANs, AGI and all sorts of acronyms that make your head spin. Let’s summarize in broad terms what’s happening: what actually triggered the current explosion, what are the implications (mixed-in with some personal speculation). As always this post is more of brain-dump with a lot of external links than a story so feel free to skip parts.
Humanity is going to make all parts of the world touched by humans beautiful. We are going to create beauty too cheap to meter. And not just an enforced-from-above standard of beauty either, everyone will be able to make their own domain beautiful in the manner of their choosing.
— Rivers Have Wings (@RiversHaveWings) January 23, 2023
Large Language Models
One of the most well-known large language models is GPT-3 (Generative Pre-training Transformer 3), developed by OpenAI. GPT-3 is a neural network-based language model that has been trained on a massive dataset, allowing it to generate human-like text. It can perform a wide range of language tasks, including translation, summarization, and question answering, with impressive accuracy. The breakthrough that made recent language models particularly game-changing was the introduction of the transformer neural architecture.
Transformers say fuck recursion! (CLIP, GPT-X)
The transformer architecture is a type of neural network architecture that was introduced in a 2017 paper “Attention is All You Need” by Google researchers. It is particularly well-suited for tasks involving sequential data, such as natural language processing and speech recognition. It’s a radically new approach to neural architecture that brought to market a lot of new products.
The key feature of the transformer architecture is the use of self-attention mechanisms. Attention mechanisms allow the model to focus on specific parts of the input, rather than processing the entire input at once. The self-attention mechanism allows the model to weigh the importance of different parts of the input sequence when making a prediction. The input sequence is processed by a stack of multiple layers, each layer consisting of two sub-layers: a multi-head self-attention mechanism and a fully connected feedforward neural network. The self-attention mechanism allows the model to weigh the importance of different parts of the input sequence and the feedforward neural network allows the model to learn more complex representations of the input.
This architecture also includes a mechanism called positional encoding which allows the model to understand the order of the elements in the input sequence. This is particularly important for sequential data such as natural language sentences. Overall, it allows the model to efficiently process large amounts of sequential data (hence the “Large” in “Large Language Models”) and achieve state-of-the-art performance on a variety of NLP tasks such as language translation, text summarization, and language modeling. It’s really this novel neural architecture that enabled the current breakthroughs in AI tech including the flurry of image generation tools.
Image Generation Tools
Image generation tools have also gained a lot of attention in recent years. One example is DALL-E, also developed by OpenAI, which is a neural network-based image generation tool. DALL-E can generate a wide range of images based on a given text prompt, such as “the soul of transhumanism, painting by Greg Rutkowski”. The generated images are often highly realistic and can be used in a variety of applications, including design and art.

In the past other image generation tools have also been developed, such as StyleGAN and BigGAN. These tools can generate high-resolution images of people, animals, and other objects with great detail and realism. But the recent image generation improvements all have in common the introduction of CLIP, the mysterious codename of a very special transformer.
WTF is CLIP???
CLIP (Contrastive Language-Image Pre-training), which came out in early 2021 is a machine learning model developed by OpenAI that can understand the relationship between natural language and visual information. It is trained on a large dataset of images and their associated text captions.
The model is pre-trained on this dataset using a process called contrastive learning. During this process, the model is shown two different pieces of information (e.g. an image and a caption) and is trained to determine whether or not they are related. The model is then fine-tuned on specific tasks such as image captioning, image-text retrieval, or text-image retrieval.
Its transformer architecture allows the model to efficiently process large amounts of data and achieve state-of-the-art performance on a variety of NLP tasks. CLIP made any “text-to-image” tool possible which seemed non-trivial not that long ago.
Diffusion models as a catalyst
At first (essentially last year, in 2021) CLIP was paired with the GANs we knew and loved since the beginning like VQGAN. I remember very fondly the summer of 2021 spending all night long playing with CLIP+VQGAN, barely sleeping and marvelling at this nascent aesthetic. It gave us a pair of goggles or a microscope to observe the latent world but soon enough we managed to somehow optimize the way we develop the digital photographs of latent concepts. Indeed soon after the release of a new paper diffusion models took over and rapidly replaced GANs, well simply because they seem to work a lot better. There we had it, a new micro-extinction event in the machine-learning industry: “Diffusion Models Beat GANs on Image Synthesis”. Depending on your level of expertise you can dig into the math side of it which sheds some light on the denoising process.
Where does the data come from?
At first and in some ways these deep-fake enabling technologies do feel like the ultimate heist. The training data is scraped with or without permission directly from the Internet. For image generation one of the best datasets available is LAION-5B which contains 5.85 billion CLIP-filtered image-text pairs. The fact that it contains a mixed bag of human representations and commercial content is highly controversial and later iterations of Stable Diffusion allowed artists to opt-out of being part of the dataset. I personally believe that having some of my art in there as well as some personal photographs should be celebrated as being part of the beautiful shared sum of human culture as long as the dataset is made public.
What is Dreambooth?
One of the holy grails of AI visual art has been to generate more variations of the same and back in the days of StyleGAN there were 2 problems: firstly one needed to feed the machine a large collection of the same concept and secondly, after a cumbersome (and expensive!) training, the results were far from being aesthetically interesting at all. My production for the exhibition of 2020 called Serotonin Depletion was based on StyleGAN-2 and I was not very happy with all the results. Dreambooth, published in August 2022 (note : and since then many more similar techniques like LoRA have sprouted up), changes all of that and enables embedding of concepts inside image generation tools in a fairly inexpensive way, with very little material and absolutely incredible results.
It has become very easy to fine-tune a generalist model like Stable Diffusion on a few samples of a concept or person. More than that since the fine-tuning process is rather straightforward and cheap it has enabled a whole scene of custom diffusion models where hobbyists compete for generating the best results in the most creative ways possible, mixing and matching different existing networks with an palette of techniques that keeps growing. The potential use cases for this technique are numerous and diverse, I would say this is currently the most exciting ongoing growth of any AI sector. One thing worth noting is that openness and the DIY ethos of StabilityAI was amplified by this accessible Dreambooth technique (authored by Google Research and originally working with their proprietary diffusion engine called Imagen) for which most implementations rely on Stability’s Stable Diffusion itself! What a great, bizarre-yet-encouraging synergy!
A new modular media format
The end result of a fine-tuning process is usually a .ckpt file, a checkpoint file representing a new artificial frozen “brain” state or some sort of compressed visual space. This type of file has effectively become a new medium, an artistic expression materialized in a few gigabytes of latent-space. It is composable (checkpoints can be merged), editable (infinitely finetunable), modular (the output of one can be plugged into another), a ground-breaking generative primitive that will have deep repercussions on modern art far beyond the current neo-popart shallow vibe mostly carried out by sweaty neckbeard ML waïfu researchers and subterranean perverts. The beauty of this new alien tool resides in the existing concepts it seems to intersect, namely:
- it feels like a new compression mechanism for visual media
- it is explored like some sort of a new camera
- it is used by artists like a visual synthesizer
Implications and Ethical Considerations 🤔
Overall, the recent boom in large language models and image generation tools has exciting implications for a wide range of industries and applications. While there are certainly ethical concerns to consider, the potential for these tools to improve and augment human capabilities is undeniable and overall text really is the universal interface.
The competitive edge of schizopoasting vs GPT-ass text
As stated above LLMs make it incredibly easy and cheap to generate your average text content, basic stories, courses, blog articles, legal documents, boring emails, copywriting for art magazines, customer support interactions, exhibition descriptions that noone reads and much more. Predictably this evolution brings more value to the specificities of human writing including but not limited to extreme aversion to cohesive language and schizoposting. Humans posters have to post weirder and better, find the outer limits of creative writing where patterns become more intricate, less structured. GPT-ass text has become slur just like NPC. Humans are excellent at detecting subtle shifts and twists in fellow humans’ expression and making most of human writing a platitude will eventually raise the bar for what is considered interesting.
How might generative image models affect creativity?
Generative image models have the potential to greatly impact the field of digital art and design by allowing for the creation of highly realistic and unique images. However, it’s important to note that the use of these models alone does not necessarily equate to creativity.
ML systems are just matrix algebra training data soup, and will only ever be as good as their training data. This is why AlphaZero is only as good as human players at Chess and Go :)
— flaw (@flawedaxioms) January 1, 2023
The impact on visual arts
Each new wave of technological evolution has a deep impact on the way new works of art are created. Every iteration is instantly recognizable but reaching a broadening scope. I remember looking at some StyleGAN-2 visuals thinking this was truly interesting until the CLIP+VQGAN came along and took over, some of the works meeting quite some success in 2021. Later on even more advanced tooling came along, namely tools like Midjourney, and redefined once more what is the expected standard of a generated image. As John Rafman recently pointed out on the New Models podcast (down below, at minute 44) there is some sort of morale imperative to capture this transient aesthetic while it’s still there, all the little glitches and quirks have become symbols that need cherishing not erasure.
Will AI create jobs and new art forms?
Whispering the right sentences to these systems is becoming an art called “prompt-engineering” with numerous guides written on the topic. This skill is used interchangeably for visuals and text generation, it is both the celebration of text as the ultimate medium and a very uncanny mirror into the impact of language on the collective mind.
Is it safe for the environment?
Replacing Google Search with something like ChatGPT has the potential to dramatically increase the carbon emissions of the Internet because this would replace a simple database lookup query with a full-blown neural net inference which is significantly more resource intensive.
Which industries will be affected/nuked by AI first?
Big Tech 
These technologies have a great potential to shuffle the cards for a lot of the big actors in the tech industry. All industry players want a piece of the cake but the amount of competent cooks is still in relative low-supply. We’re bound to witness a lot mercato-like transactions for AI ‘rockstar’ researchers and a flurry of failed AI products. Some companies like Microsoft are already fumbling the bag rather grotesquely in a way that reminds previous catastrophes.
Software-engineering
The job of a software engineer is also changing dramatically and the future of the job market remains unclear. Code completion tools are becoming more and more efficient and I believe that in the near future platforms like Github might be able to generate and merge code straight from the Kanban board to the master (or main) branch of any project which should considerably reduce the number of required maintainers.
SEO
Generative tools are bound to have a huge impact on the Internet because they supercharge the world of programmatic SEO. Existing rankings can be used as input for generative tools which triggers an interesting feedback loop involving machines ranking machine generated content for machines to parse and rank. This Ourboros-like mechanism can potentially magnify the Dead Internet Theory.
Tech-adjacent sectors
There are other industries that are likely to be affected by generative image models in the near future.
- Digital art and design: Generative image models can be used to create highly realistic images, which could be used in a variety of digital art and design projects.
- Film and video game production: image models can be used to create realistic, computer-generated characters, environments, and special effects. There are indie proof-of-concepts pretty good at making concept art.
- Advertising and marketing: image models can be used to generate photorealistic images for ads and marketing campaigns.
- Architecture and urban planning: image models can be used to generate photorealistic images of architectural designs, which could be used for presentations and visualizations.
- Fashion and retail: image models can be used to generate images of clothing and accessories, which could be used for online shopping and virtual try-on features.
- Automotive and industrial design: image models can be used to generate images of vehicles and industrial products, which could be used for visualization and marketing purposes.
Is AGI possible?
The pipe dream of a Artificial General Intelligence is becoming more and more tangible and there’s a been quite a consensus shift towards considering it imminent. A few years ago this was only a wild speculation held by mostly weirdos and outlandish-yet-decorated visionaries like Ray Kurzweil but recently a lot of seasoned front-row professionals in the industry have done a full 180 degrees among which: Yann Lecun, Katherine Crowson (@RiversHaveWings), John Carmack (![]() ), Andrej Karpathy, Joscha Bach, Demis Hassabis and many more brilliant (but obviously a little bit biased) characters. Even more concerning: the company that solved protein-folding, Go and Starcraft 2 is now on an explicitly stated mission to engineer general purpose agents which should in itself represent a rather blatant bull flag for the whole industry.
), Andrej Karpathy, Joscha Bach, Demis Hassabis and many more brilliant (but obviously a little bit biased) characters. Even more concerning: the company that solved protein-folding, Go and Starcraft 2 is now on an explicitly stated mission to engineer general purpose agents which should in itself represent a rather blatant bull flag for the whole industry.
Legendary programmer John Carmack literally said 60% chance of AGI by 2030, 95% by 2050 in his latest interview. He says its inevitable at this point. It's time to get your soul right. We're about to meet God
— sucks (@powerbottomdad1) February 5, 2023
Besides, the general public is getting their first glimpses of the uncanny valley through consumer-facing prototypes which bridge the conceptual gap and create sensational headlines. GPT-3 existed long before ChatGPT but the introduction of a friendly UI on top of it suddenly made the popularity of the underlying model explode! My personal take on this whole spiritual ordeal is that indeed the genie is slowly, but more and more rapidly, flowing out of its silicon shell and it will be extremely difficult to pinpoint the anticipated realization and even more difficult to forecast its impact. We’re collectively in uncharted territory and we should all be as psyched about this as the moon landing in 1969.
A surprising number of people: pic.twitter.com/UtKi9CaPwH
— Eigil - abstr/acc 💎 (30867/50000 words) (@Ayegill) February 13, 2023
Further-down-the-drain-type-of-take
Not only do I think something colossal is coming but ironically it just absolutely mogged every single one of us starting with the one area we thought untouchable : the blurry notion of creativity, however one defines it. “Creative” writing and visual art absolutely demolished/revolutionized in the span of a couple of years: the taunt is real and incredibly humbling.
Where and how to experiment with these new technologies?
All these new shiny toys have in common the fact that they necessitate on average beefy GPUs (<16Gb VRAM need not apply) to run. In the case of the language models like GPT-3 they can be very unwieldy for the average consumer and thus require to be used as a service. Meanwhile image generation networks can be trained (maximum resource intensivity, Stable Diffusion training cost 600k $) AND used (inference is less costly, few cents per shot) on custom servers or locally which makes the technology less prone to centralization.

Local PC
Should you buy a cool expensive consumer GPU for your tower PC? One problem is that the minute you buy it its value starts decreasing and slowly drifting away in a very competitive market. Additionally maintaining a local environment for the GPUs can be tedious and sometimes re-provisioning would be faster with a cloud solution where you can just scrap the entire thing and start anew. This would not be a massive pain in the ass if the machine-learning community adopted something else than Python for building most its tooling but it is what it is.
Using SaaS tools
This area is moving extremely fast and includes players that have rapidly become household names. These are the companies making the headlines and being used by journalists to comment on the advent of the machine age. Besides the obvious convenience they do promote a monolithic approach to creative walled gardens. Indeed these services are very easy to use but are heavily censored and hold a questionable attitude towards the rights of the content produced. In your user journey it should definitely be the first step though, a friendly way to get a feeling for what the technology is capable of with the least amount of effort.
- ChatGPT: one of the fastest growing userbase in recent tech history
- Midjourney: a sort of meta cohesive customer driven art direction which I have yet to enjoy
- Dall-e 2: the OG heavily censored image magic box
- Copilot: a programming assistant incredibly effective
Running your own models using Cloud GPUs
In this case you would rent GPUs in the cloud and pay hourly for your usage. This approach allows for more fine-grained control and experimentation. Here are some providers I have tried so far and a list and of pros and cons arguments for each of them.
Colab
| PROS |
CONS |
|---|---|
| Really good community support | |
| Rather cheap | Not very user friendly |
| Not good for long-running workflows | |
| Paid-tier got recently nerfed | |
| No file persistence |
Paperspace
| PROS |
CONS |
|---|---|
| 8$ monthly pro sub | Lots of bugs |
| Lots of cool features | The “official” adapted notebooks are buggy af :/ |
| Gradient Notebook IDE is cool | Limited availability of machines |
| Limited availability of paid-tier machines too |
Use this tutorial to get Automatic1111’s WebUI up and running. Don’t use the stuff mentioned on their blog lol ![]()
JarvisLabs
| PROS |
CONS |
|---|---|
| Cheap rates | Shitty barebones UI |
| Pre-defined images like Automatic1111’s | No flat-rate offer |
Conclusion
Generative tools are deeply changing our world and it is very likely that the current technological prowess is barely the tip of the iceberg. History is in the making and the levers to get a front row seat have never been easier to use, affordable and readily available. Now is the perfect time to take a peek at the future of media production, “creativity” and potentially our species! ![]()
Disclaimer: this article was written using LLMs for the actual information, my own brain for the unhinged takes, my beloved HHKB and illustrated with Stable Diffusion 1.5.